PÅ FARTEN? LYTT ELLER SE
Oppsummering
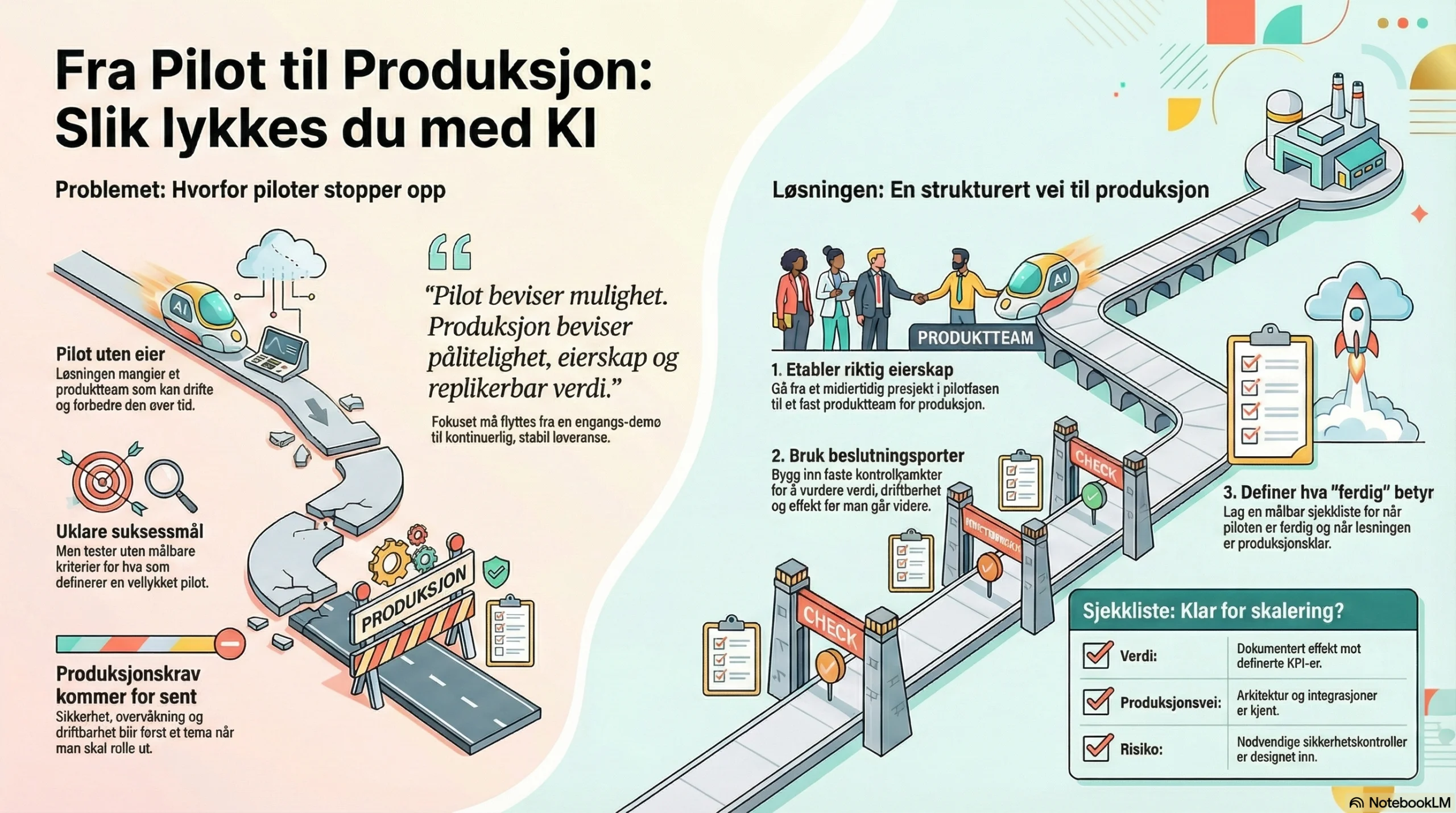
Mange KI-initiativ ser lovende ut i pilot, men faller i overgangen til produksjon fordi kravene endrer seg: fra «fungerer det?» til «fungerer det stabilt, sikkert, målbart – og kan det driftes og skaleres?». Denne artikkelen viser en praktisk vei fra pilot til produksjon med riktig leveransemodell, beslutningsporter og en konkret sjekkliste for skalering.
1. Hvorfor så mange piloter stopper før produksjon
Piloter feiler sjelden fordi «modellen ikke virker». De feiler fordi produksjon krever mer enn modellkvalitet: robuste dataflyter, driftbarhet, sikkerhet, etterprøvbarhet, og eierskap i linja. Gartner har eksplisitt pekt på at generativ KI-prosjekter ofte blir forlatt etter proof of concept på grunn av blant annet datakvalitet, uklare forretningsgevinster, økte kostnader og svake risikokontroller [1]. Det samme mønsteret går igjen når Gartner omtaler agentiske KI-initiativ: prosjekter stoppes når verdi er uklar og risiko/kost blir høy [2].Tre typiske «pilot-feller» du bør unngå:
- Pilot som prosjekt uten hjem: ingen verdistrøm/produktteam som kan eie løsningen i drift.
- Uklare suksessmål: «vi tester» uten målbare kriterier for go/no-go.
- Produksjonskrav kommer for sent: logging, sikkerhet, monitorering og endringskontroll oppdages først når du skal rulle ut.
2. Pilot vs produksjon: hva som faktisk endrer seg
I pilot optimaliserer du for læring og tempo. I produksjon må du optimalisere for stabilitet, kvalitet over tid og ansvarlighet. I praksis betyr dette at kravene flytter seg fra «kan vi demonstrere effekt?» til «kan vi levere effekt kontinuerlig, med akseptabel risiko og drift?». Google sitt «Rules of ML» understreker at ML-produkter i produksjon er systemer som må vedlikeholdes, overvåkes og itereres – ikke engangsleveranser [3]. Forskning på «teknisk gjeld» i ML-systemer peker på at raske gevinster ofte skjuler løpende vedlikeholdskostnader når systemet møter virkeligheten [4].En nyttig huskeregel: Pilot beviser mulighet. Produksjon beviser pålitelighet, eierskap og replikerbar verdi.
3. Leveransemodell: fra prosjekt til produkt og verdistrøm
Skal du fra pilot til produksjon, trenger du en leveransemodell som tåler det du faktisk prøver å gjøre: levere verdi over tid. Bekk beskriver at valg av leveransemodell (linje, prosjekt, produkt) handler om hvilken risiko og usikkerhet du må håndtere – ikke om trender [5]. For KI betyr det ofte: pilot kan drives som prosjekt, men produksjon bør eies i en produkt-/verdistrøm-logikk der ansvar for effekt, drift og forbedring ligger fast.Et praktisk mønster som fungerer i mange virksomheter:
- Produkt/verdistrøm eier «hvorfor»: effektmål, prosessendring, opplæring, forankring.
- Plattform/IT og data eier «hvordan»: sikkerhet, integrasjoner, drift, dataprodukter.
- Governance eier «rammer»: risikovurdering, kontrollspor, beslutningsprotokoll og dokumentasjon.
Hvis løsningen kan være høyrisiko (eller bare forretningskritisk), må du tidlig planlegge for sporbarhet og kontroll. EU-kommisjonens AI Act «service desk» beskriver for eksempel krav om automatiske loggfunksjoner for høyrisiko KI-systemer gjennom livsløpet [6]. Du trenger ikke gjenta regelverket her – men du må designe for det. (Se også vår artikkel om kontrollspor og måleplan i praksis: AI Act i praksis: ansvarlig KI-utrulling som gir målbare resultater.)
4. Beslutningsporter: kontroll uten å miste fart
Beslutningsporter er «smidighetens sikkerhetsbelte»: du kan jobbe iterativt, men stoppe opp ved definerte punkter og verifisere at du fortsatt bygger riktig løsning – og at forutsetningene for skalering er oppfylt. Metier forklarer at gode beslutningsporter gir ledelsen kontroll, tydeliggjør beslutninger og reduserer risikoen for å fortsette med prosjekter som ikke lenger gir mening [7]. Tre beslutningsporter som dekker 80 %:- Port 1 – etter pilot: Oppnådde vi definert effekt? Har vi bevis på verdi og gjennomførbarhet?
- Port 2 – før produksjon: Er løsningen driftbar (monitorering, sikkerhet, integrasjoner, beredskap)?
- Port 3 – etter utrulling: Ser vi stabil effekt i drift, og har vi kontroll på avvik og forbedring?
AWS sin «Five V’s»-tilnærming legger vekt på å binde sammen verdi, suksessmålinger og en konkret vei til produksjon – nettopp for å unngå at piloter blir stående som isolerte eksperimenter [8].
5. Definition of done: tydelig slutt på pilot og tydelig start på drift
«Definition of done» er det mest undervurderte styringsverktøyet i KI-prosjekter. Uten det sklir piloten ut i tid, eller går i produksjon uten å være produksjonsklar.Definition of done for pilot bør være målbar og knyttet til business. AWS anbefaler eksplisitt å definere suksessmål som kobles til forretningsresultat tidlig i løpet, som del av å «visualize» effekt og ansvar [8]. Det er også i tråd med anbefalinger i Google Cloud sine retningslinjer for å utvikle ML-løsninger som fungerer som forventet i produksjon, inkludert verifikasjon/validering og monitorering [9].
Definition of done for produksjon må i tillegg dekke driftbarhet og risiko. Google-forskere har publisert en konkret «rubric» med tester og overvåkningsbehov for produksjonsmodenhet (28 områder) som et svar på hvor krevende det er å gjøre ML robust i drift [10]. NIST sin AI Risk Management Framework fremhever TEVV (testing, evaluation, verification, validation) som en gjennomgående disiplin gjennom hele livsløpet [11].
Praktisk minimum for «done – produksjon»:- Teknikk: testregime, versjonering, rollback-plan, skaleringsstrategi.
- Data: datakvalitet, tilgangsstyring, datalinjering (lineage) der relevant.
- Drift: monitorering av ytelse og kvalitet over tid, alarmer, incident-prosess.
- Styring: dokumentert eierskap, beslutningslogg, kontrollspor/måleplan der nødvendig.
6. Hva må være sant før skalering?
Før du skalerer, må du validere hypotesene som faktisk avgjør om løsningen kan gi gevinst i større skala. Bekk beskriver at hypoteser om tidsbesparelse, investeringer og organisatoriske forutsetninger bør avdekkes tidlig og testes, slik at man står sterkere når løsninger skal skaleres og gevinster realiseres [12]. Det er et praktisk «anti-pilot-paralyse»-grep: du tester ikke bare modellen – du tester om virksomheten tåler løsningen. Sjekkliste: «klar for skalering»- Verdi: dokumentert effekt mot definerte KPI-er (ikke bare «god demo»).
- Produksjonsvei: kjent arkitektur og integrasjoner; ingen «mystery plumbing» igjen.
- MLOps/LLMOps: plan for deploy, monitorering, re-trening/prompt-endringer, versjonering.
- Driftskapasitet: support/forvaltning er bemannet, og incident-prosess er avklart.
- Risiko & compliance: relevante kontroller er designet inn (bl.a. logging der nødvendig) [6].
AWS har også publisert en MLOps-sjekkliste som et verktøy for å vurdere modenhet og avdekke hull i systemdekning – nyttig både før og etter produksjonssetting [13].
7. Mini-case: fra pilot i kundeservice til produksjon
Illustrerende eksempel: En virksomhet piloterer en KI-assistent som foreslår svarutkast til kundeservice. I pilot måles reduksjon i svartid og økt løsningsgrad. Når piloten lykkes, kommer produksjonskravene:- Det etableres et produktteam (kundeservice + IT + data) som eier effekt og drift.
- Det defineres beslutningsporter: etter pilot, før utrulling til flere team, og etter 30 dager i drift.
- «Done – produksjon» inkluderer monitorering av kvalitet over tid, loggføring av nøkkelhendelser, og rutiner for eskalering når KI foreslår feil.
Poenget er ikke verktøyvalget, men strukturen: leveransemodell + beslutningsporter + tydelig «done» gjør at du kan rulle ut raskt uten å miste kontroll.
8. Prøv nå
Begynn med ett konkret use case (45–60 min): Skriv «definition of done – pilot» og «definition of done – produksjon». Inkluder 3 målbare effektmål, 5 produksjonskrav (drift/sikkerhet/monitorering), og hvem som eier hvert punkt. Bruk dette som beslutningsgrunnlag ved første port.Kilder
- Gartner. Gartner Predicts 30% of Generative AI Projects Will Be Abandoned After Proof of Concept by End of 2025 (Press release, 29. juli 2024). Les kilde
- Gartner. Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 (Press release, 25. juni 2025). Les kilde
- Google for Developers. Rules of Machine Learning (oppdatert 25. august 2025). Les kilde
- Sculley, D. mfl. Hidden Technical Debt in Machine Learning Systems (NeurIPS, 2015). Les kilde
- Bekk. Produkt eller prosjekt: et spørsmål om risiko (8. desember 2025). Les kilde
- EU-kommisjonen (AI Act Service Desk). AI Act – Article 12: Record-keeping. Les kilde
- Prosjektbloggen (Metier). Hvorfor trenger vi prosjektmodeller med gode beslutningsporter (Anders Tellefsen). Les kilde
- AWS. Beyond pilots: A proven framework for scaling AI to production (24. oktober 2025). Les kilde
- Google Cloud Architecture Center. Guidelines for developing high-quality, predictive ML solutions (8. juli 2024). Les kilde
- Breck, E. mfl. (Google Research). A Rubric for ML Production Readiness and Technical Debt Reduction (2017). Les kilde
- NIST. Artificial Intelligence Risk Management Framework (AI RMF 1.0) (NIST AI 100-1, 2023). Les kilde
- Bekk. Eksperimentering: verifisering av potensial (5. desember 2025). Les kilde
- AWS Prescriptive Guidance. Evaluating your ML project with the MLOps checklist. Les kilde