PÅ FARTEN? LYTT ELLER SE
Oppsummering
Verdien av KI kommer først når løsningen tåler drift: stabile resultater, kontrollerte endringer, forutsigbar kost, målbar effekt og rask håndtering av avvik. Det krever et minimum av MLOps/LLMOps: evals, monitorering, versjonering og en fast forbedringssyklus.
For høyrisiko KI er post-market monitoring og hendelsesrapportering dessuten eksplisitte krav til leverandører. [1][2]
1. Drift er der ROI skapes (eller dør)
En pilot kan se “smart” ut uten å være lønnsom. I drift blir dere målt på:- Stabil effekt: resultatene holder seg over tid (ikke bare i demo).
- Kontroll: dere vet hva som er endret, hvorfor det ble endret, og hva konsekvensen ble.
- Kost: dere har kontroll på tokens/compute, latency, lisens og driftstid.
- Risiko: dere fanger avvik tidlig og har tiltak (guardrails, fallback, menneskelig kontroll).
Dette er kjernen i NIST sitt syn på KI som et sosioteknisk system som må styres gjennom livsløpet – ikke bare bygges. [3]
2. MLOps vs LLMOps: hva som er likt, og hva som er annerledes
MLOps handler om CI/CD/CT for prediktive modeller (data → trening → deployment → monitorering). Google beskriver MLOps som rammeverk for kontinuerlig leveranse og automatisering gjennom livsløpet. [4]LLMOps har samme driftlogikk, men med ekstra friksjon:
- Ikke-determinisme: samme input kan gi ulik output (du trenger evals, ikke bare enhetstester). [5]
- Prompt + policy er “kode”: endringer må versjoneres, testes og kunne rulles tilbake.
- Data blir ofte innhold: RAG/knowledge-baser, dokumenter, søk – og dermed “content drift”.
- Sikkerhet: prompt injection, datalekkasje, uønsket atferd → krever guardrails og logging.
Praktisk konsekvens: dere trenger evals + monitorering som førsteprioritet, ellers vet dere ikke hva dere faktisk har satt i drift. [6]
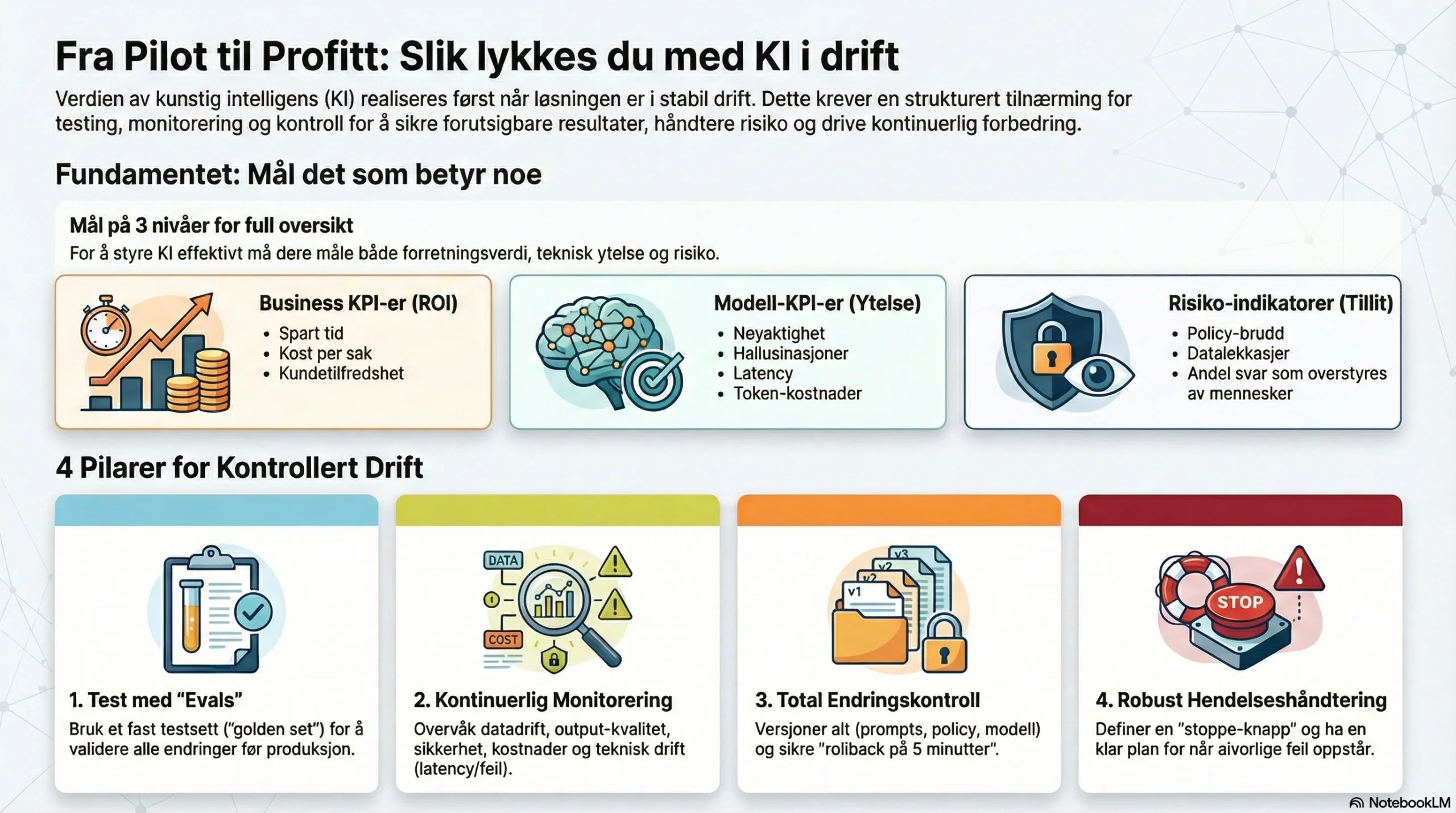
3. Tre metrikklag: business, modell og risiko
Hvis dere vil ha kontinuerlig forbedring uten kaos, må dere måle på tre lag samtidig: Lag A – Business KPI (ROI):- Tidsbruk per sak / prosess
- Første-respons / gjennomløpstid
- Kvalitetsmål (kundetilfredshet, feilrate, rework)
- Kost per transaksjon / per sak
- Oppgaveløsningsgrad (task success), “groundedness”/kildebruk, presisjon
- Hallusinasjonsindikatorer (f.eks. svar uten kilder i RAG)
- Latency, throughput
- Kost (tokens/compute) per sak
- Policy-brudd (sensitiv info, uønsket innhold)
- Avvikshendelser og eskaleringer
- Adopsjon: andel saker som godkjennes/overstyres av menneske
NIST AI RMF gir et nyttig rammespråk for å knytte disse lagene til styring (Govern), kontekst (Map), måling (Measure) og tiltak (Manage). [3]
4. Evals som motor: test før du slipper, test mens du drifter
For generativ KI er evals det nærmeste dere kommer “unit tests”. OpenAI beskriver evals som metode for å teste og forbedre systemer i produksjon på tross av variasjon. [5] Minimum eval-regime (som faktisk virker):- Golden set: 50–200 representative eksempler dere eier (inkl. vanskelige hjørnetilfeller).
- Rubric: hva er “godt svar” (fakta, tone, policy, kilder, format).
- Gating: ingen endring til prod uten å passere terskel på golden set.
- Shadow eval: kjør ny variant parallelt i drift (uten å påvirke brukere) før release.
Som engineering-prinsipp kan dere lene dere på “ML Test Score”-tenkningen: en konkret liste over tester og monitorering som reduserer produksjonsgjeld. [7]
5. Monitorering: drift, dataskift, kvalitet, latency og kost
Monitorering må dekke både teknikk og virkning:A) Input-/datadrift: endrer brukeradferd, språk, saksområder seg?
B) Output-kvalitet: faller “task success”, øker feil eller overstyringer?
C) Sikkerhet og policy: flere policy-brudd, prompt injection-indikatorer, datalekkasje?
D) Operasjonelle SLO-er: latency, feilrate, kapasitet.
E) Kost: tokens/compute per sak, kost per uke, toppkilder til kost.
Google sine “Rules of ML” er brutalt tydelige: når data og verden endrer seg, må systemet være bygget for løpende iterasjon og overvåking – ellers vil kvaliteten gradvis svekkes uten at dere merker det i tide. [8]
6. Endringskontroll: versjoner, release-strategi og “rollback på 5 minutter”
Dette er standarden dere bør sette:- Versjonér alt: prompt, policy, retrieval-konfig, modellvalg, verktøy-kall, evalueringer.
- Release-strategi: canary (5–10% trafikk), deretter gradvis økning hvis metrikker holder.
- Rollback: én kommando tilbake til forrige “known good” (prompt+policy+modell).
- Endringslogg: hva ble endret, hvorfor, forventet effekt, faktisk effekt.
Dette er også i tråd med produksjonspraksiser for ML-systemer som vektlegger automatisering av leveranse og drift som en kontinuerlig prosess. [9]
7. Hendelser og ansvar: når KI gjør feil, hva skjer da?
Drift uten hendelsesregime blir risikabelt fort. Minimum:- Definer “alvorlig avvik” (f.eks. feil råd i helsesaker, diskriminerende output, datalekkasje, stor driftsforstyrrelse).
- Eskalering: hvem tar lead (teknisk + prosess + compliance).
- Stoppe-knapp: dere kan slå av funksjonen (fallback til standardprosess).
- Etterarbeid: root cause + tiltak + oppdatert eval-sett (slik at feilen ikke kommer tilbake).
For høyrisiko KI har EU AI Act egne krav til post-market monitoring (Art. 72) og rapportering av alvorlige hendelser (Art. 73) for leverandører av høyrisiko KI-systemer. [1][2]
8. Minimal “LLMOps stack” for norske virksomheter (50+ ansatte)
Dette er den minste pakken som gir kontroll uten å bygge et monster:- 1) Eval-harness: golden set + rubric + terskler + automatisert kjøring ved endring. [5]
- 2) Observability: logging av input/utdata (med tilgangskontroll), latency, feil, kost. [6]
- 3) Versjonering: prompt/policy/retrieval/konfig med release-notater.
- 4) Monitorering + alarmer: drift/quality/cost guardrails med terskler.
- 5) Feedback loop: “godkjent/avvist”, årsak, og datasett for forbedring.
- 6) Change board light: én ukentlig 30-min gjennomgang av metrikker og endringer.
Hvordan dette passer med Nettskred-serien: Koble driftspakken direkte til “kontrollspor/måleplan” i AI Act i praksis (uten å gjenta). Dette blir praksislaget som gjør måleplanen sann i drift.
9. Mini-case: kundeserviceassistent som forbedres uten å miste kontroll
Scenario: LLM foreslår svarutkast basert på kunnskapsbase (RAG). Målet er kortere svartid og høyere førstegangsløsning. Release 1 (2–4 uker):- Golden set: 80 ekte saker (anonymisert) + 20 “røde” cases.
- Rubric: korrekt, høflig, kildebasert, ingen sensitive opplysninger, riktig format.
- Gating: minst X% pass + ingen kritiske policy-brudd.
- Canary: 10% av sakene, kun forslag (menneske godkjenner).
- 3 KPI: tid per sak, andel forslag brukt, kvalitet/CSAT.
- 2 guardrails: hallusinasjonsindikator (svar uten kilder) + kost per sak.
- 1 forbedring: oppdater eval-sett med feil dere faktisk så i forrige uke.
Dette er “kontinuerlig forbedring” i praksis: dere bygger et system som lærer av drift, men bare innenfor kontrollerte rammer. [7]
10. Begynn her + sjekkliste
Utfør nå (60 minutter):- Velg én KI-løsning dere vil drifte neste 90 dager.
- Definer 1 business KPI + 1 quality KPI + 1 cost KPI + 1 risk KPI.
- Bygg et mini “golden set” på 30 eksempler + 10 edge cases.
- Lag en enkel rubric (5 kriterier) og kjør første eval-baseline.
- Eval-gating på plass (golden set + terskler) [5]
- Monitorering: kvalitet + latency + kost + policy
- Versjonering: prompt/policy/retrieval/konfig
- Release: canary + rollback
- Hendelsesprosess: stoppe-knapp + eskalering + etterarbeid
Referanser
- AI Act Service Desk (EU): Article 72 – Post-market monitoring by providers and post-market monitoring plan for high-risk AI systems. Kilde
- EUR-Lex: Regulation (EU) 2024/1689 (Artificial Intelligence Act). Kilde
- NIST: Artificial Intelligence Risk Management Framework (AI RMF 1.0) (NIST AI 100-1) (PDF, 2023). Kilde
- Google Cloud: Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning (White paper, May 2021). Kilde
- OpenAI: Evaluation best practices. Kilde
- OpenAI: Production best practices. Kilde
- Breck, E. m.fl. (Google): A Rubric for ML Production Readiness and Technical Debt Reduction (PDF, 2017). Kilde
- Google for Developers: Rules of Machine Learning (oppdatert 25.08.2025). Kilde
- Google Cloud Architecture Center: MLOps: Continuous delivery and automation pipelines in machine learning (28.08.2024). Kilde