PÅ FARTEN? LYTT ELLER SE
Oppsummering
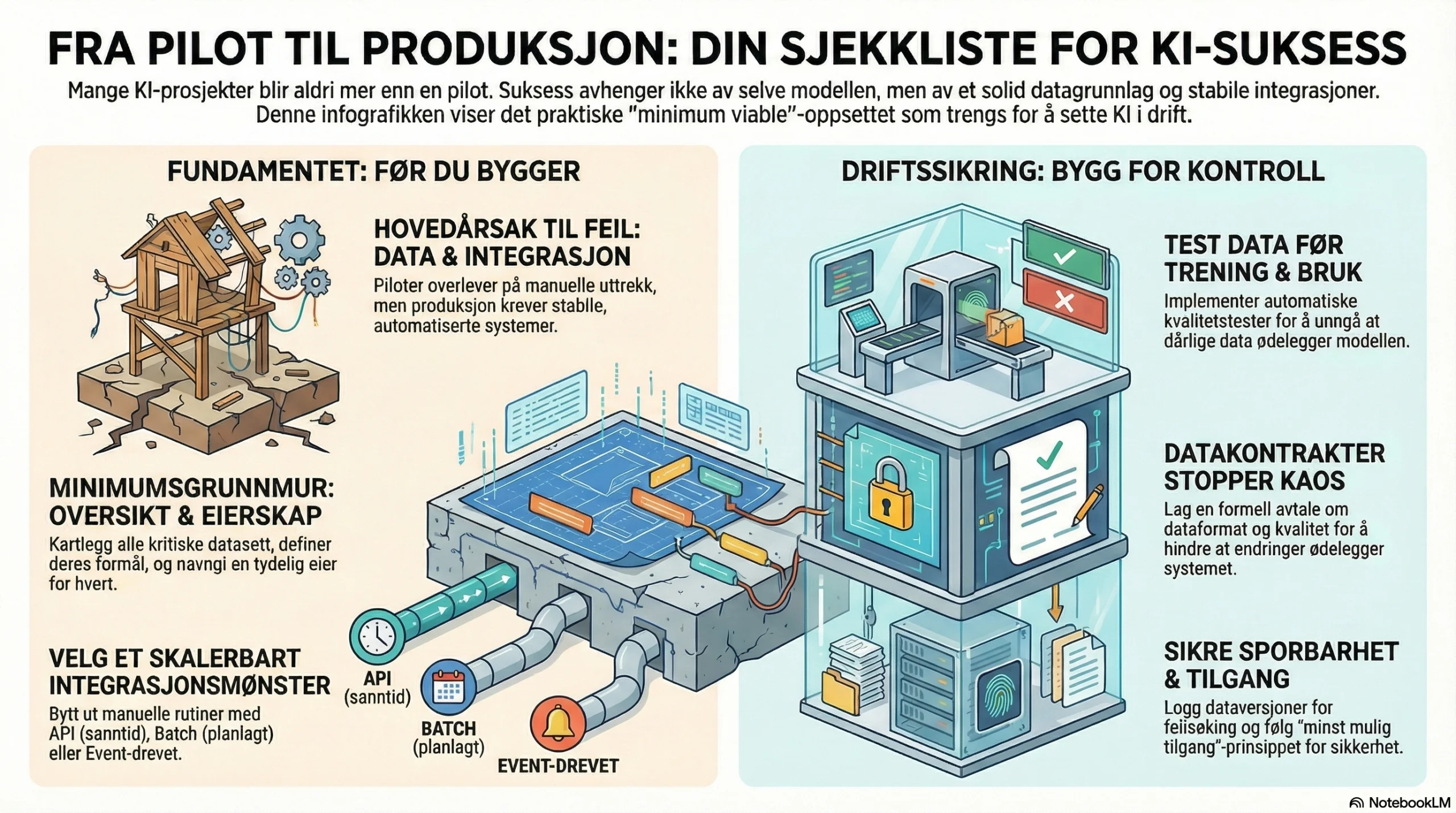
Den vanligste grunnen til at KI aldri blir mer enn pilot er datagrunnlaget og integrasjonene. I drift trenger du stabile dataflyter, tydelig eierskap, kvalitetstester, sporbarhet og tilgangsstyring. Denne artikkelen gir et praktisk 'minimum viable'-oppsett for å sette KI i drift.
For enkelte løsninger (særlig høyrisiko) blir datakvalitet, dokumentasjon og kontrollspor også et eksplisitt compliance-krav.
1. Hvorfor datagrunnlag og integrasjon er flaskehalsen
En pilot kan leve på manuelle uttrekk, tilfeldig datarensing og “best effort”. Produksjon kan ikke det. Når KI brukes i drift, blir det et system med kontinuerlig vedlikehold: nye data kommer inn, arbeidsprosesser endres, og modellen møter nye mønstre. Da må du ha kontroll på:- Hva dataene betyr (definisjoner, domene, kontekst)
- Hvor dataene kommer fra (kilder, oppdateringsfrekvens, transformasjoner)
- Hva som er “godt nok” (kvalitetstester og terskler)
- Hvem som eier hva (dataeier, prosesseier, modeleier)
- Hvem som har tilgang (minst mulig, sporbar tilgang, logging)
For høyrisiko KI er datakvalitet og datastyring ikke bare “best practice”: EU AI Act stiller eksplisitte krav til trenings-, validerings- og testdata og hvordan de håndteres (data governance).[1]
2. Minimumsgrunnmur: dataoversikt, eierskap og formål
Hvis du bare gjør tre ting før du bygger, gjør dette:- Lag en dataoversikt (hvilke datasett finnes, hvor ligger de, hvem eier dem)
- Definer formål per datasett (hva kan det brukes til, og hva kan det ikke brukes til)
- Navngi eierskap (dataeier + dataforvalter + prosesseier for use-casen)
I Norge er logikken bak Felles datakatalog nettopp å synliggjøre hvilke data virksomheter forvalter og gjøre data mer oppdagbare og gjenbrukbare.[7] DCAT-AP-NO er en standard for å beskrive datasett og datatjenester med felles metadata, som gjør at data faktisk kan finnes og brukes i praksis.[8]
Praktisk minimum: Start med et enkelt “dataset card” per kritisk datasett (maks én side): kilde, eier, oppdateringsfrekvens, felter, definisjoner, tilgang, sensitivitet, og kjente kvalitetsproblemer.
3. Integrasjon som tåler drift: mønstre som funker (og hva du unngår)
KI i produksjon handler sjelden om å “kjøre en modell”. Det handler om å få data inn, få beslutning/støtte ut, og få resultat tilbake til prosessen. Tre integrasjonsmønstre som skalerer:- API-first (tjenesteintegrasjon): KI-tjenesten henter/leverer via stabile API-er. Best når prosessen trenger sanntid eller lav ventetid.
- Batch/ELT (dataplattform): KI trenes/oppdateres på planlagte kjøringer. Best når prosessen tåler etterslep og datakvalitet er viktigere enn responstid.
- Event-drevet (hendelser): KI trigges av hendelser (ny sak, ny kunde, ny ordre). Best når du vil ha sporbarhet og tydelige triggere.
Det du bør unngå i produksjon: CSV-er på e-post, manuelle eksport/import-rutiner, og “skjulte” integrasjoner som bare én person forstår. Det blir dyrt, risikabelt og umulig å drifte.
Google sin veileder for ML-kvalitet understreker behovet for robuste trenings- og serving-systemer, og kvalitetstiltak gjennom hele livsløpet – ikke bare modelltrening.[2]
4. Datakvalitet i praksis: test før du trener, test før du serverer
Datakvalitet er ikke et prosjekt – det er en løpende praksis. Minstekravet er at du tester data både:- før trening (slik at du ikke trener på feil/bias/feilformat)
- før serving (slik at modellen ikke får “søppel inn” i drift)
Microsoft beskriver datakvalitetsregler som sentrale for å sikre integritet og pålitelighet, og peker på dimensjoner som nøyaktighet, konsistens og fullstendighet som typiske kjernekrav.[10] I praksis betyr det at du lager en liten “test-suite” for data: obligatoriske felt, gyldige verdier, rimelige intervaller, duplikater, og oppdateringsfrekvens.
Eksempel på minimumstester (5 stk):- Andel manglende verdier på kritiske felter < X%
- Dato/tid innenfor forventet intervall
- Ingen “uventede” kategorier (eller de flagges eksplisitt)
- Duplikatrate under terskel
- Freshness: datasettet er oppdatert innen Y timer/dager
Verktøy er valgfritt, men poenget er ikke. Hvis du vil teste data som kode, finnes etablerte open source-praksiser for data-validering (for eksempel test-/forventningsbaserte rammeverk).[12]
5. Datakontrakter: den raske måten å stoppe “schema chaos”
Når én avdeling endrer et felt (navn, type, betydning), ryker ofte hele use-casen. Datakontrakter er en enkel og effektiv motvekt: en versjonert avtale mellom produsent og konsument om schema, semantikk, kvalitet og oppdateringsfrekvens.En praktisk definisjon brukt i moderne dataplattformer er at en datakontrakt er et “løfte” om kvalitet og struktur mellom produsent og konsument (inkludert schema, freshness og kvalitetstester).[11]
Minimum datakontrakt (1 side / YAML/JSON):- Schema (felter, typer)
- Semantikk (hva betyr feltene)
- Kvalitetsregler (f.eks. freshness + null-rate)
- Versjonering (hvordan endringer gjøres uten å brekke konsumenter)
- Eierskap og kontaktpunkt
6. Lineage og observability: når noe blir feil må du kunne forklare hvorfor
I drift kommer dette spørsmålet før eller siden: “Hvorfor ble resultatet annerledes i dag?” Da må du kunne spore:- Hvilke data gikk inn (og hvor kom de fra)
- Hvilke transformasjoner ble gjort
- Hvilken modell/versjon/prompt/konfigurasjon ble brukt
OpenLineage beskriver lineage som en åpen standard for å samle metadata om datasett, jobber og kjøringer – nettopp for å forstå påvirkning av endringer og finne rotårsak ved feil.[9]
Praktisk minimum: Logg datasettversjon (eller tidsstempel), transformasjonsjobb, modellversjon og output. Ikke vent til “plattformen en dag”. Gjør det fra første produksjonssetting.
7. Tilgang, logging og personvern: bygg “secure by default”
KI tar ofte i bruk datasett som inneholder personopplysninger eller forretningskritiske opplysninger. Da bør du designe etter prinsippet “data protection by design and by default”: minimér, begrens tilgang, og slett når det ikke lenger trengs.[5] EDPB sin veiledning til artikkel 25 (innebygd personvern) understreker de grunnleggende prinsippene (formålsbegrensning, dataminimering, lagringsbegrensning, integritet/konfidensialitet og ansvarlighet) og hvordan de bør operasjonaliseres i systemdesign.[6] Minimum sikkerhetsoppsett for KI i drift:- Minst mulig tilgang (rollenivå, ikke “alle med lenken”)
- Separasjon mellom trening og produksjonsdata der det er hensiktsmessig
- Audit logging på tilgang og kritiske endringer
- Rutiner for avvik/hendelser (hvem gjør hva når noe går galt)
8. Definition of done for data og integrasjon
Hvis dere vil unngå å “gå i produksjon på håp”, bruk denne Definition of done (minimum):- Dataoversikt: kritiske datasett dokumentert (dataset cards), eierskap navngitt
- Integrasjon: valgt mønster (API/batch/event) med dokumentert ansvar og feilhåndtering
- Datakvalitet: minimum 5 kvalitetstester med terskler (og alarmer)
- Datakontrakt: schema + semantikk + freshness + versjonering
- Lineage/observability: sporbarhet på datasettjobb + modellversjon
- Tilgang og logging: minst mulig tilgang + audit på kritiske operasjoner
For en mer helhetlig livsløpstankegang (kvalitet, drift, skala, automatisering), er Googles MLOps-rammeverk et nyttig referansepunkt for hva som typisk trengs når ML-systemer industrialiseres.[3]
9. Mini-case: kundeservice-assistent som faktisk kan rulles ut
Use-case: KI foreslår svarutkast basert på historiske saker og kunnskapsbase. Minimum data/integrasjon for drift:- Datakilder: saks-/ticket-system + kunnskapsbase + produkt-/kundeinfo
- Integrasjon: API for å hente sak og skrive forslag tilbake (eller event ved “ny sak”)
- Kvalitetstester: sakskategorier, språk, manglende felter, freshness på KB
- Kontrakt: hvilke felter KI får se (og hvilke den aldri får se)
- Logging: hvilke kilder ble brukt, hvilken versjon, og hvem godkjente før sending
Hvor ROI vanligvis skapes: tidsreduksjon per sak + bedre første-respons + høyere løsningsgrad. Men dette krever at dataflyten faktisk er stabil og målebar i drift (ikke manuell).
10. Mikrosteg i dag
45–60 minutter: Velg ett use-case og gjør “minimum viable data”-øvelsen:- List opp 3 datasett dere må ha (kilde + eier + sensitivitet).
- Lag ett “dataset card” (maks én side) for det viktigste datasettet.
- Definer 5 kvalitetstester + terskelverdier.
- Velg integrasjonsmønster (API/batch/event) og skriv én setning om hvorfor.
- Skriv en mini-datakontrakt: schema + freshness + kontaktpunkt.
Referanser
- EU-kommisjonen (AI Act Service Desk): Article 10: Data and data governance. Les kilde
- Google Cloud Architecture Center: Guidelines for developing high-quality, predictive ML solutions (08.07.2024). Les kilde
- Google: Practitioners guide to MLOps (whitepaper, PDF). Les kilde
- NIST: Artificial Intelligence Risk Management Framework (AI RMF 1.0) (PDF, 2023). Les kilde
- Datatilsynet: Data Protection by Design and by Default. Les kilde
- European Data Protection Board (EDPB): Guidelines 4/2019 on Article 25 Data Protection by Design and by Default (PDF). Les kilde
- Altinn / Digitaliseringsdirektoratet: Felles datakatalog – data.norge.no. Les kilde
- data.norge.no: DCAT-AP-NO – standard for beskrivelse av datasett, datatjenester og begreper. Les kilde
- OpenLineage: About OpenLineage (åpen standard for lineage-metadata). Les kilde
- Microsoft Learn: Data quality rules in Unified Catalog (Purview) (04.12.2025). Les kilde
- DataHub Docs: Data Contracts. Les kilde
- Great Expectations: Data validation workflow (OSS docs). Les kilde